
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 대용량데이터 처리방안
- 오라클
- 구름Level
- K-MOOC 3주차
- K-MOOC 매치업 강좌
- 1주차:메타데이터와 데이터표준화
- 고전압안전
- ETCL
- 마이데이터 개념과 원칙
- 대용량 데이터 Batch
- 코딩테스트
- 마이데이터 비즈니스 모델
- 코테
- 데이터 이행
- 데이터 허브
- 계층적질의문
- 측정계
- 무결성제약조건
- dbms
- K-MOOC
- 2주차 : ETL/CDC
- 마이데이터 개념
- EBH
- 2022 마이데이터 국민참여단 후기
- 대용량 데이터 처리
- sql
- 마이데이터 국민참여단
- 백준
- GROUP함수
- 대용량 데이터 이행
- Today
- Total
어제보다 더 나은 나
DBMS(오라클) : 서브쿼리, DDL, DML, DCL, TCL, 시퀀스 본문
* 서브쿼리 : 하나의 SQL 명령문의 결과를 다른 SQL 명령문에 전달하기 위해 2개 이상의 SQL 명령문을 하나의 SQL 명령문으로 연결하여 처리하는 방법
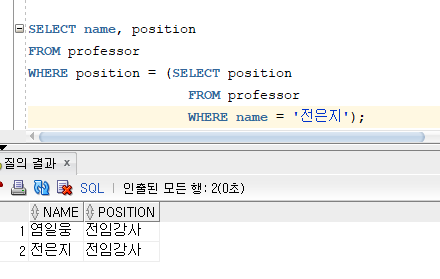
=> 서브쿼리는 메인쿼리가 실행되기 전에 한번씩 실행됨
=> 서브쿼리에서 실행된 결과가 메인 쿼리에 전달되어 최종적인 결과를 출력
* 단일행 서브쿼리
=> 서브쿼리에서 단 하나의 행만을 반환하여 메인쿼리에 반환하는 질의문
=> 메인쿼리의 WHERE 절에서 서브쿼리의 결과와 비교할 경우에는 반드시 단일행 비교 연산자 중 하나만 사용해야 함
(=, > , >=, <, <=, <>)



* 다중행 서브쿼리
=> 서브쿼리에서 반환되는 결과 행이 하나 이상일 때 사용하는 서브쿼리
=> 메인쿼리의 WHERE 절에서 서브쿼리의 결과와 비교할 경우에는 다중 행 비교 연산자를 사용하여 비교
(다중 행 비교 연산자 : IN, ANY, SOM, ALL, EXISTS)
(다중 행 비교 연산자는 단일 행 비교 연산자와 결합하여 사용 가능)
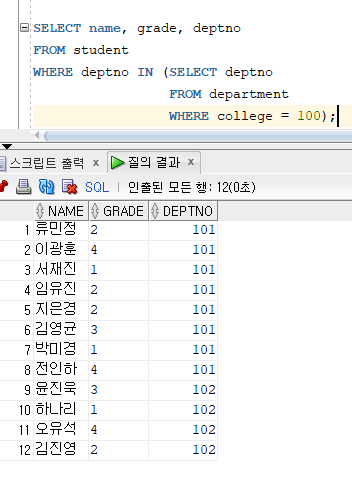
* IN 연산자 :
=> 메인쿼리의 비교조건에서 서브쿼리의 출력 결과와 하나라도 일치하면 메인쿼리 조건절이 참이 되는 연산자
=> '=' 연산자를 'OR'로 연결한 결과 같은 의미
* ANY 연산자 :
=> 메인 쿼리의 비교 조건에서 서브 쿼리의 출력 결과와 하나라도 일치하면 메인쿼리 조건절이 참이 되는 연산자
=> '>, <'등과 같은 범위 비교도 가능
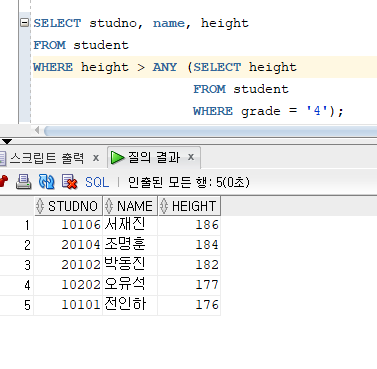
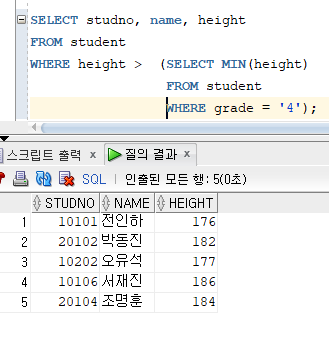
=> 결과적으로 ANY 연산자는 SELECT절에 MIN을 적용한 것과 같다.
* ALL 연산자
=> 메인 쿼리의 비교 조건에서 서브쿼리의 검색 결과와 모두 일치하면 메인 쿼리 조건절이 참이 되는 연산자
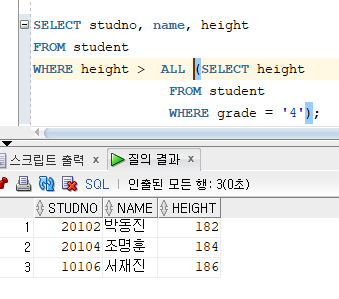
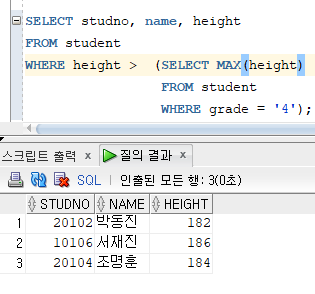
=> 결과적으로 ALL 연산자는 SELECT절에 MAX를 적용한 것과 같다.
* EXISTS 연산자
=> 서브쿼리에서 검색된 결과가 하나라도 존재하면 메인쿼리 조건절이 참이 되는 연산자
=> 서브쿼리에서 검색된 결과가 하나라도 존재하면 메인쿼리 조건절이 거짓이 되는 연산자
('선택된 레코드가 없습니다'라는 메시지 출력)
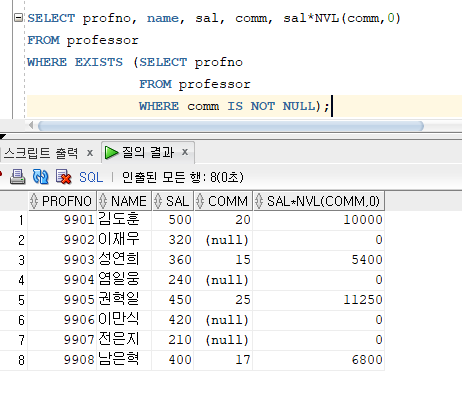
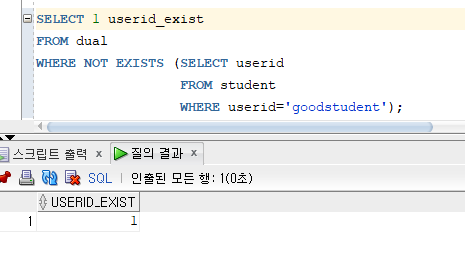
* NOT EXISTS 연산자 : EXISTS 연산자와 상반되는 연산자
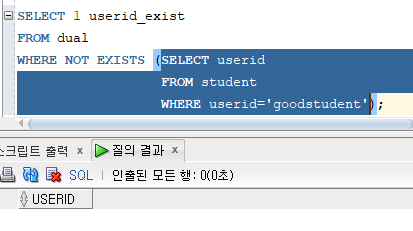
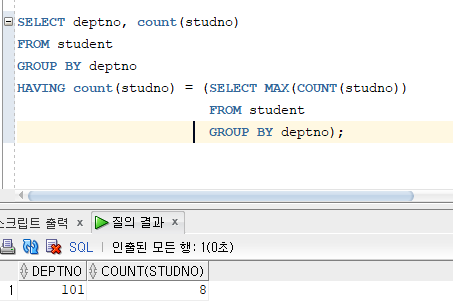
# 예제 : 학과별 학생 수가 가장 많은 학과의 번호와 학생의 수를 출력하세요.
* 다중 컬럼 서브 쿼리
=> 서브쿼리에서 여러 개의 칼럼 값을 검색하여 메인 쿼리의 조건절과 비교하는 서브쿼리
=> 메인쿼리의 조건절에서도 서브쿼리의 칼럼 수만큼 지정해야 함
* PAIRWISE : 칼럼을 쌍으로 묶어서 동시에 비교하는 방식 (반드시 비교하는 칼럼의 수는 동일해야 함)
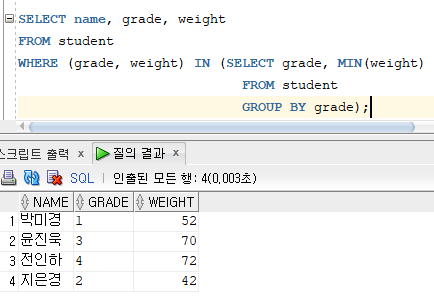
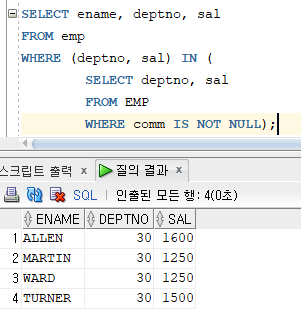
# 예제 : 사원 테이블을 조회하여 각 부서별로 최대 급여를 받는 사람을 출력하여라.
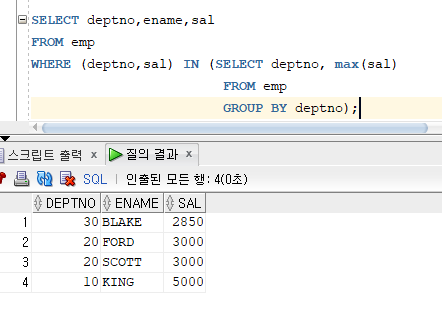
* UNPAIRWISE : 칼럼별로 나누어서 비교한 후, AND 연산을 하는 방식
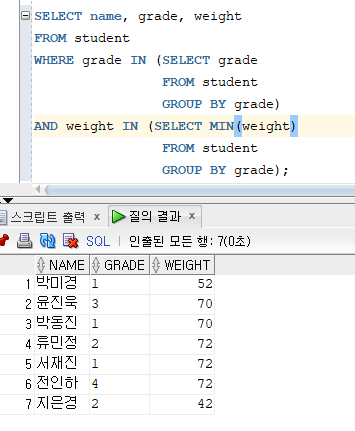
해설 : 학년이 1,2,3,4 중 하나이고, 몸무게가 42, 52, 70, 72 중 하나와 같으면 참이다. PAIRWISE에서 출력이 안된 학생들이 출력이 된다.
* 상호연관 서브쿼리
=> 메인쿼리절과 서브쿼리 간에 검색결과를 교환하는 서브쿼리
=> 메인쿼리와 서브쿼리간의 결과를 교환하기 위해서 서브쿼리의 WHERE 조건절에서 메인쿼리의 테이블과 연결
=> 행을 비교할 때마다 결과를 메인으로 반환하는 관계로 처리 성능이 저하될 수 있음.
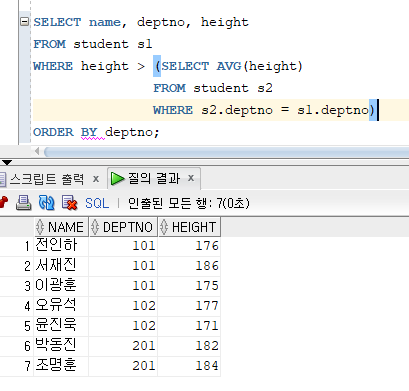
* 서브쿼리 사용시 주의사항
1. 복수행 값을 반환하는 서브쿼리와 단일행 비교연산자를 함께 사용하는 경우, 오류 발생
2. 반환되는 칼럼의 수와 메인쿼리에서 비교되는 칼럼 수가 일치하지 않는 경우, 오류 발생
3.서브쿼리 내에서 ORDER BY 절 사용하는 경우, 오류 발생
4. 서브쿼리의 결과가 NULL 인 경우
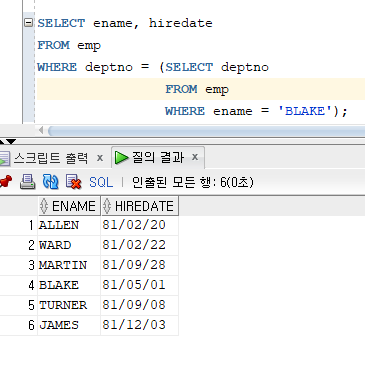
# 예제 : BLAKE와 같은 부서에 있는 모든 사원에 대해서 사원이름과 입사일을 디스플레이 하라
# 예제 : 평균 급여 이상을 받는 모든 사원에 대하여 사원번호와 이름을 디스플레이 하는 질의문을 생성하라. 단 출력은 급여를 기준으로 내림차순으로 정렬하라.
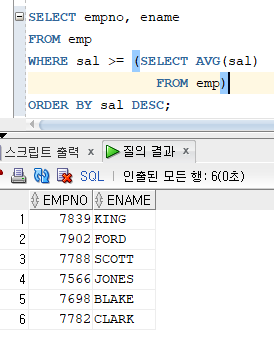
* 스칼라 서브쿼리 :
=> 오직 하나의 값만 반환
=> 반환되는 값의 데이터형은 서브 쿼리에서 선택된 데이터형과 일치
=> 소량의 데이터의 경우에는 효과적이나 대량의 데이터의 경우 성능 저하 가능
* 데이터 조작어 (DML)
=> 테이블에 새로운 데이터를 입력하거나 기존 데이터를 수정, 삭제하기 위한 명령어
(INSERT, UPDATE, DELETE, MERGE)
* 데이터 입력
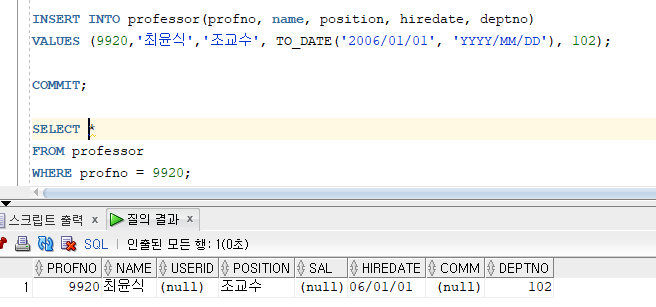
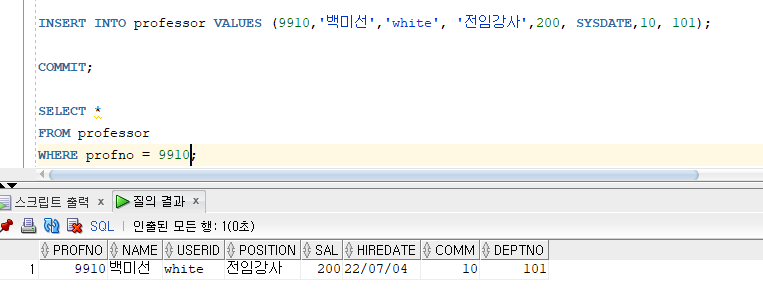
* INSERT INTO ~ VALUES ~
=> INTO 절에 명시한 칼럼에 VALUES 절에서 지정한 칼럼 값을 입력
=> INTO 절에 칼럼을 명시하지 않으면 테이블 생성 시 정의한 칼럼순서와 동일한 순서로 입력
=> CHAR, VARCHAR2, DATE 타입의 입력데이터는 단일인용부호('')로 묶어서 입력
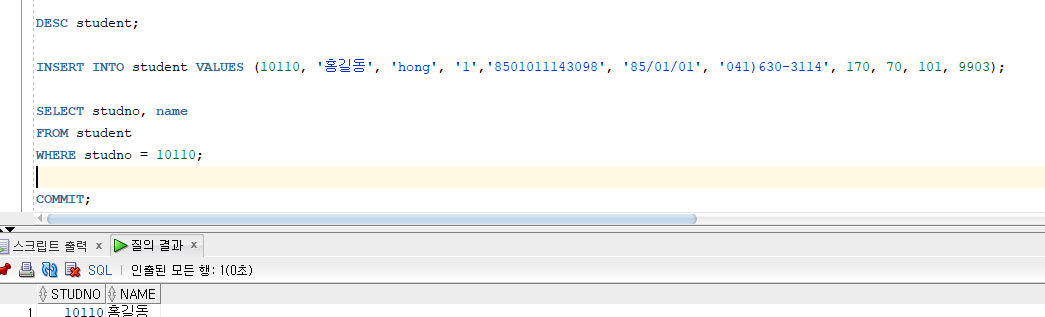
* NULL 입력
=> 데이터를 입력하는 시점에서 해당 칼럼 값을 모르거나, 미확정
=> 묵시적인 방법 : INSERT INTO 절에 해당 칼럼 이름과 값을 생략
(해당 칼럼에 NOT NULL 제약조건이 지정된 경우 불가능)
=> 명시적인 방법 : VALUES 절의 칼럼에 NULL, '' 사용
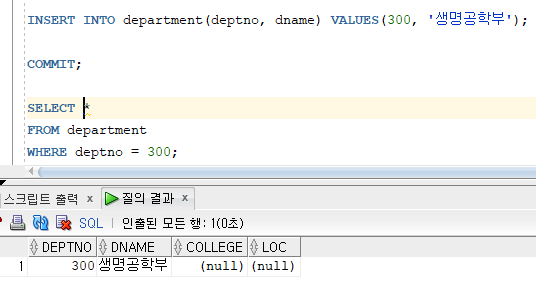
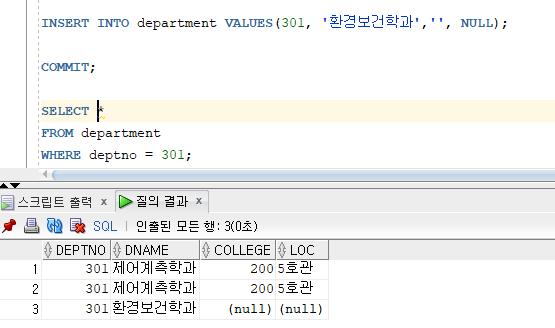
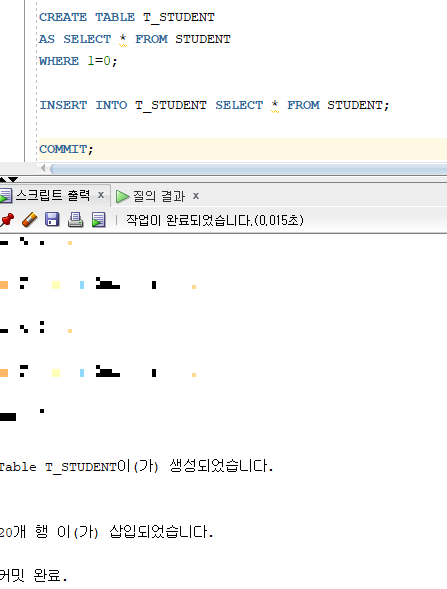
* 다중 행 입력 방법
=> INSERT 명령문에서 서브쿼리 절을 이용
=> INSERT 명령문에 의해 한번에 여러 행을 동시에 입력
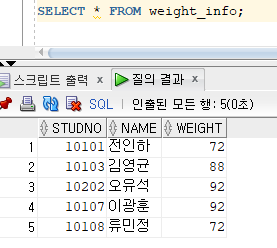
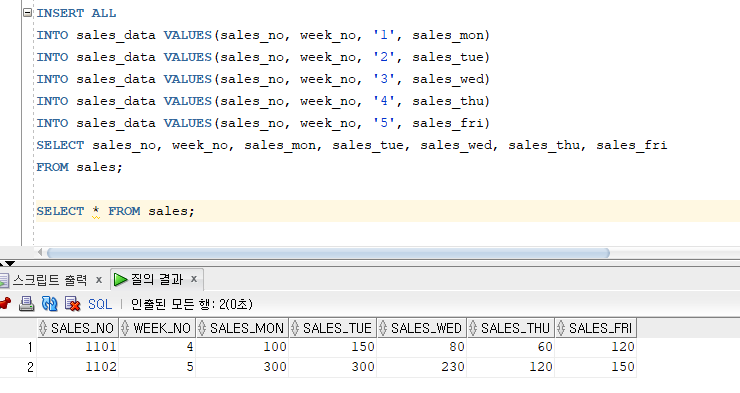
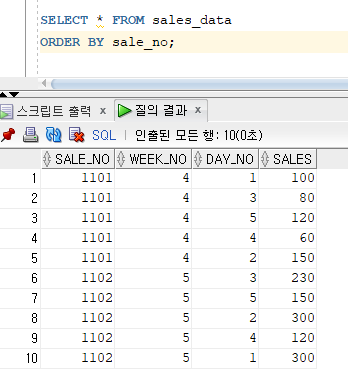
* INSERT ALL
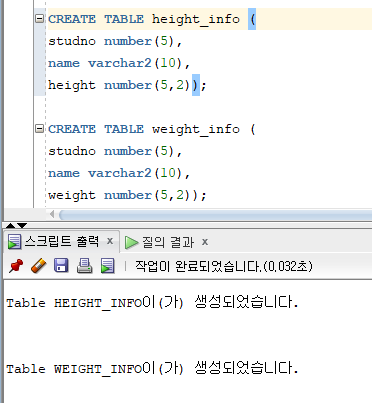
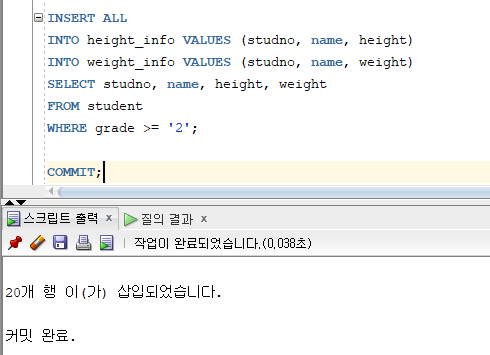
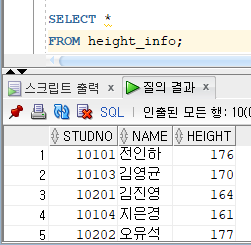
* Conditional INSERT ALL 명령문
=> 서브쿼리의 결과 집합에 대해 WHEN 조건절에서 지정한 조건을 만족하는 행을 해당되는 테이블에 각각 입력
=> 서브쿼리에서 검색된 행을 만족하는 조건이 여러 개일 경우 해당 테이블에 모두 입력
=> ALL : WHEN ~ THEN ~ ELSE의 조건을 만족하는 서브쿼리의 모든 검색 결과를 입력하기 위한 옵션
=> WHEN 조건절 THEN : 서브쿼리의 결과집합에 대한 비교 조건
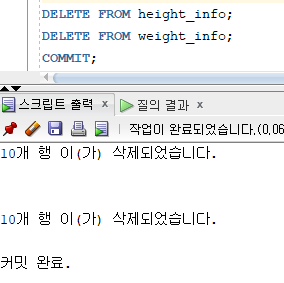
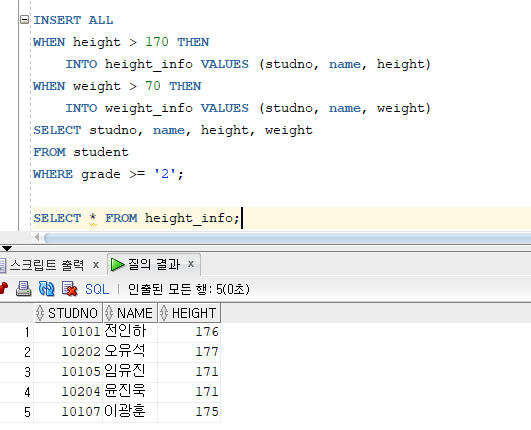
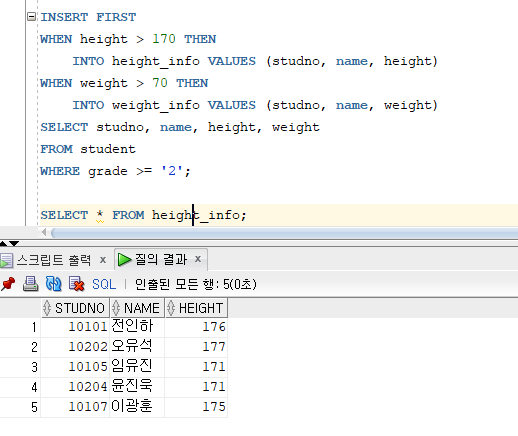
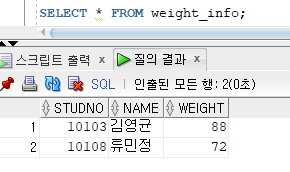
* Conditional-First INSERT
=> 서브쿼리의 결과 집합에 대해 WHEN 조건절에서 지정한 조건을 만족하는 행들을 첫 번째 테이블에 우선적으로 입력하기 위한 명령문
=> 서브쿼리의 결과 집합 중에서 조건을 만족하는 행들을 첫 번째 WHEN절에서 지정한 테이블에만 입력하고 그 외의 결과행들의 집합에서 첫 번째 조건에 INSERT한 행을 제외하고 나머지 WHEN절에 INSERT, 마지막에는 ELSE절에 정의된 TABLE에 INSERT
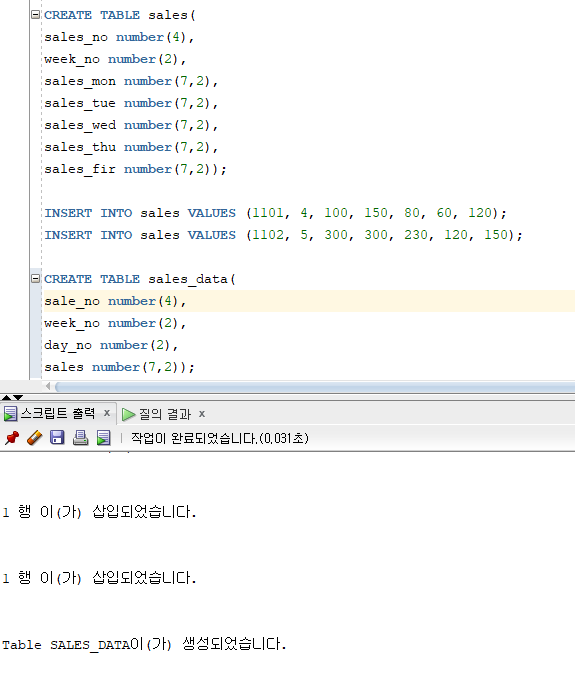
* PIVOTING INSERT 명령문
=> OLTP 업무에서 사용되는 데이터를 데이터웨어하우스 업무에서 사용되는 분석용 데이터로 변환하는 경우에 사용
=> 하나의 행을 여러가지 행으로 나누어서 입력하는 기능
=> Unconditional INSERT ALL 명령문과 거의 동일
=> INTO 절에서 하나의 테이블만 지정
* 데이터 수정
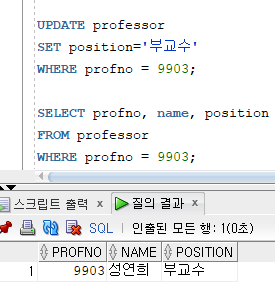
=> UPDATE 명령문은 테이블에 저장된 데이터 수정을 위한 조작어
=> WHERE 절을 생략하면 테이블의 모든 행을 수정
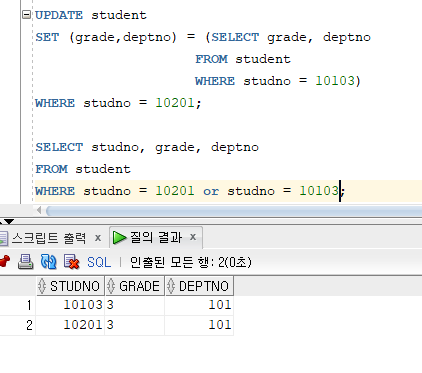
=> SET절에서 서브쿼리를 이용
=> 다른 테이블에 저장된 데이터를 검색하여 한꺼번에 여러 칼럼을 수정
=> SET절의 칼럼 이름은 서브쿼리의 칼럼 이름과 달라도 됨
=> 데이터 타입과 칼럼 수는 반드시 일치
# 예제 : 교수 테이블에서 이만식 교수의 직급과 동일한 직급을 가진 교수들 중 현재 급여가 450이 안되는 교수들의 급여를 12% 인상하세요.
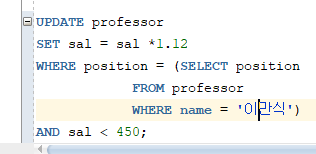
* 데이터 삭제
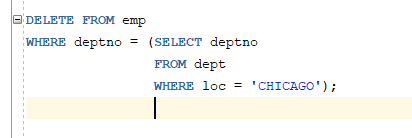
=> DELETE 명령문 : 테이블에 저장된 데이터 삭제를 위한 조작어
=> WHERE 절을 생략하면 테이블은 모든 행 삭제

=> WHERE 절에서 서브쿼리 사용
=> 다른 테이블에 저장된 데이터를 검색하여 한꺼번에 여러 행의 내용을 삭제함
=> WHERE 절의 칼럼 이름은 서브쿼리의 칼럼 이름과 달라도 됨
=> 데이터 타입과 칼럼 수는 일치해야 함
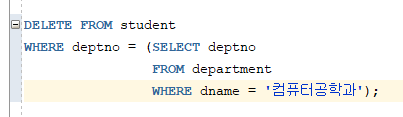
# 예제 : 서브쿼리를 이용하여 사원테이블에서 CHICAGO에 근무하는 사람들을 삭제하세요 (EMP, DEPT)
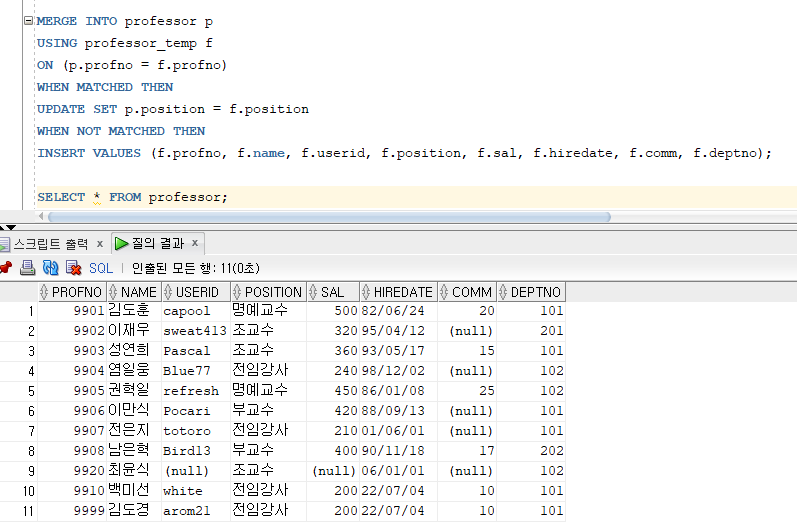
* MERGE
=> 구조가 같은 테이블을 비교하여 하나의 테이블로 합치기 위한 데이터 조작어
=> WHEN 절의 조건절에서 결과 테이블에 해당 행이 존재하면 UPDATE 명령문에 의해 새로운 값으로 수정, 그렇지 않으면 INSERT 명령문으로 새로운 행을 삽입
=> 대량의 데이터를 분석하기 위한 업무에 유용
* 트랜잭션 관리
=> 관계형 데이터베이스에서 실행되는 여러 개의 SQL 명령문을 하나의 논리적 작업 단위로 처리하는 개념
=> COMMIT : 트랜잭션의 정상적인 종료
(트랜잭션 내의 모든 SQL 명령문에 의해 변경된 작업 내용을 디스크에 영구적으로 저장하고 트랜잭션을 종료)
(해당 트랜잭션에 할당된 CPU, 메모리 같은 자원이 해제)
=> ROLLBACK : 트랜잭션의 전체 취소
(트랜잭션 내 모든 SQL 명령문에 의해 변경된 작업 내용을 전부 취소하고 트랜잭션을 종료)
(해당 트랜잭션에 할당된 CPU, 메모리 같은 자원을 해제, 트랜잭션을 강제 종료)
* 시퀀스
=> 유일한 식별자
=> 기본 키 값을 자동으로 생성하기 위하여 일련번호 생성 객체
=> 여러 테이블에서 공유 가능
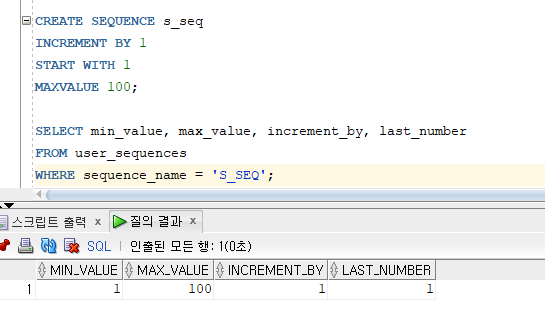
=> 시퀀스를 조회할 때는 대문자를 사용할 것

=> 기본키로 사용할 수 있는 적절한 칼럼이 없거나 다수의 칼럼을 결합해야 식별이 가능한 경우에는 시퀀스를 이용
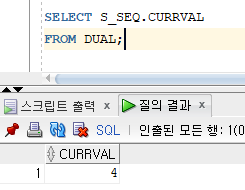
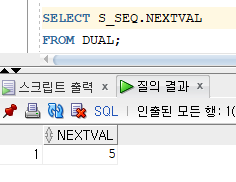
* 시퀀스 정의 변경
=> 시퀀스 생성 후 증가치, 최소값, 최대 값등의 정의를 수정
=> 변경된 시퀀스 정의는 새로 생성되는 시퀀스 값부터 적용
=> ALTER SEQUENCE 명령문을 사용하여 변경
=> START WITH절은 생성 직후의 시작 값을 의미, 변경 불가
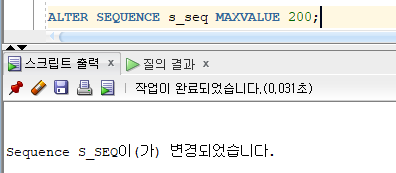
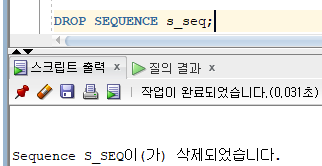
* 시퀀스 삭제
=> DROP SEQUENCE 명령문을 사용하여 삭제
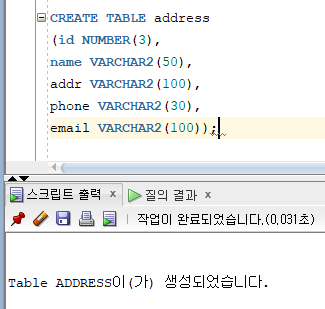
* 테이블 관리
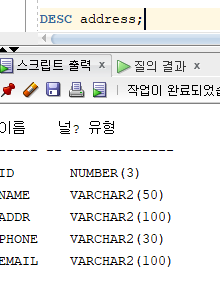
* 테이블 생성
=> 테이블에 대한 구조를 정의하고 데이터를 저장하기 위한 공간을 할당하는 과정
=> 테이블을 구성하는 칼럼의 데이터 타입과 무결성 제약조건을 정의하는 과정
=> 대소문자 구별 없음, 소문자로 저장하려면 단일 인용부호 사용
=> 서로 다른 테이블에서 동일한 데이터를 저장하는 칼럼 이름은 가능하면 같은 이름을 사용할 것
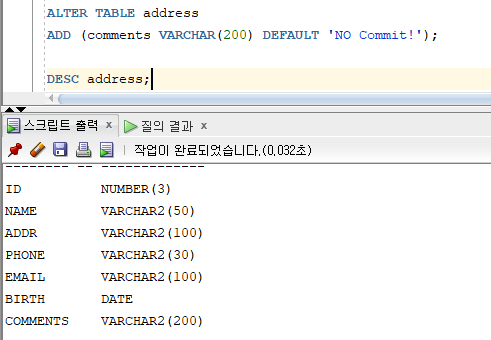
* DEFAULT 옵션
=> 칼럼의 입력 값이 생략될 경우에 NULL 대신에 입력되는 기본 값을 지정하기 위한 기능
=> 칼럼이나 의사칼럼 (NEXTVAL, CURRVAL) 사용 불가
* 서브 쿼리를 이용한 테이블 생성
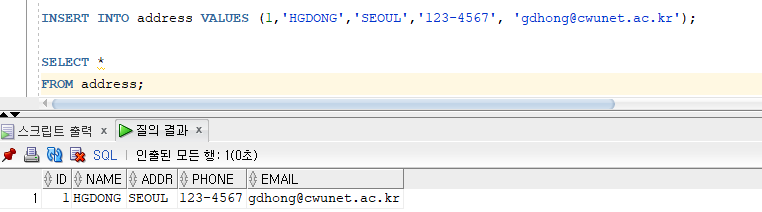
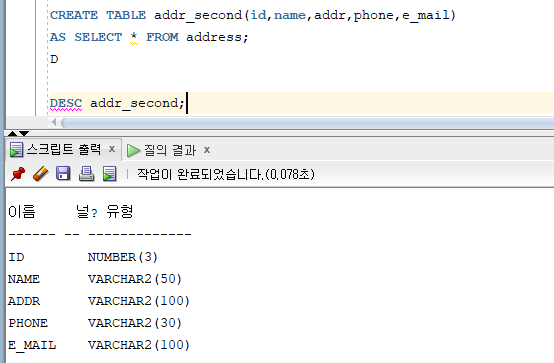
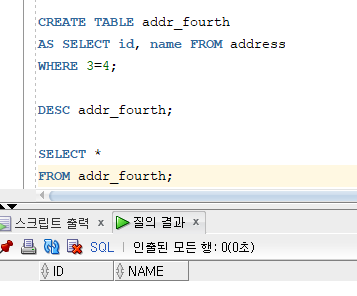
* 기존 테이블의 구조만 복사
=> 서브쿼리를 이용한 테이블 생성 시 데이터는 복사하지 않고 기존 테이블의 구조만 복사 가능
=> 서브쿼리의 WHERE 조건절에 거짓이 되는 조건을 지정하여 출력 결과 집합이 생성되지 않도록 지정
( Ex. WHERE 1=2 (출력결과가 항상 거짓인 조건을 명시) )
* 테이블 구조 변경
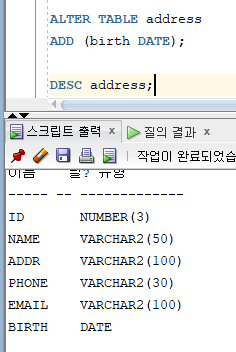
=> ALTER TABLE 명령문 이용
=> 칼럼 추가 시, ALTER TABLE ... ADD 명령문 사용
=> 추가된 칼럼은 테이블의 마지막 부분에 생성, 위치 지정 불가능
=> 수정할 테이블에 기존 데이터가 존재하면 칼럼 값은 NULL로 입력
* 테이블 칼럼 삭제
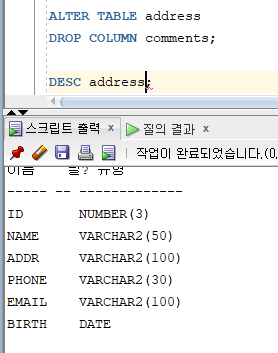
=> 테이블 내의 특정 칼럼과 칼럼의 데이터를 삭제
=> ALTER TABLE ... DROP COLUMN 명령문 사용
=> 2개 이상의 칼럼이 존재하는 테이블에서만 사용 가능
=> 하나의 칼럼 삭제 명령문은 하나의 칼럼만 삭제 가능
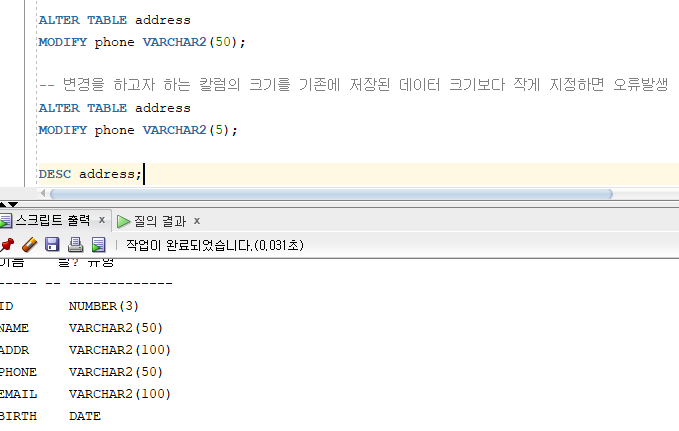
* 테이블 칼럼 변경
=> 테이블에서 칼럼의 타입, 크기, 기본 값 변경가능
=> ALTER TABLE ... MODIFY 명령문 이용
=> 기존 칼럼에 데이터가 없는 경우 : 칼럼 타입이나 크기 변경이 자유로움
=> 기존 칼럼에 데이터가 존재하는 경우 :
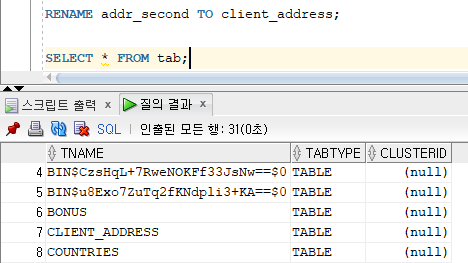
* 테이블 이름 변경
=> RENAME 명령문 사용 : 객체 이름을 변경하는 DDL 명령문. 뷰, 시퀀스, 동의어 등과 같은 데이터베이스 객체의 이름 변경 가능.
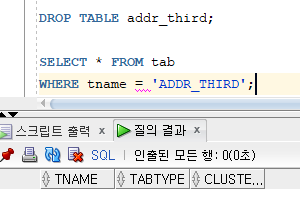
* 테이블 삭제
=> 기존 테이블과 데이터를 모두 삭제
=> DROP TABLE 명령문 사용
=> 삭제된 테이블 칼럼에 대해 생성된 인덱스도 함께 상제
=> 삭제된 테이블과 관련된 뷰와 동의어 'invalid' 상태
=> 삭제할 테이블의 기본 키나 고유 키나 다른 테이블에서 참조하고 있는 경우 삭제 불가능
=> 참조하고 있는 테이블(자식테이블)을 먼저 삭제
* TRUNCATE 명령문
=> 테이블 구조는 그대로 유지하고, 테이블의 데이터와 할당된 공간만 삭제
=> 테이블에 생성된 제약조건과 연관된 인덱스, 뷰, 동의어는 유지
* DELETE 명령문과 TRUNCATE 명령문과의 차이점
=> DELETE : 기존 데이터만 삭제하는 명령, ROLLBACK 가능, WHERE 절을 이용하여 특정 행만 삭제 가능
=> TRUNCATE : 기존 데이터 삭제와 물리적인 저장공간까지 반환하는 명령, DDL문이므로 ROLLBACK 불가능, WHERE 절을 이용하여 특정 행만 삭제 불가능
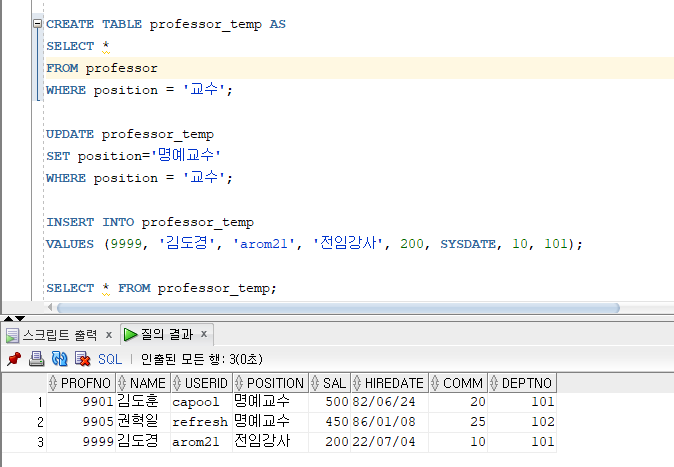
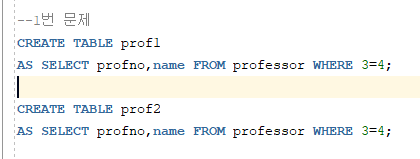
1. 교수 테이블에서 교수 번호, 교수 이름으로 구성된 테이블 PROF1, PROF2를 생성해 보세요.
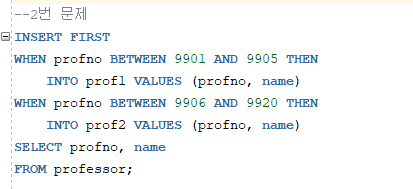
2. 교수 테이블에서 교수 번호가 9901~9905까지인 교수의 교수번호와 이름은 prof1 테이블에 입력 교수 번호가 9906~9920까지인 교수의 교수번호와 이름은 prof2 테이블에 입력 입력해 보세요.
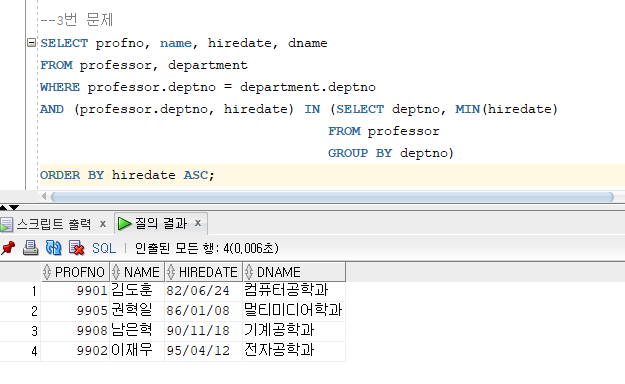
3. 각 학과별로 입사일이 가장 오래된 교수의 교수번호와 이름, 입사일, 학과명을 출력하세요.
(입사일 순으로 정렬하세요.)
교수 NO. 교수명 입사일 학과
===== ===== ===== ===========
9901 김도훈 82/06/24 컴퓨터공학과
9905 권혁일 86/01/08 멀티미디어학과
9908 남은혁 90/11/18 기계공학과
9902 이재우 95/04/12 전자공학과
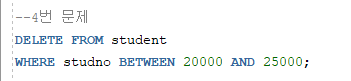
4. 학생 테이블에서 학번이 20000에서 25000번에 해당하는 학생들을 삭제하세요.
5. EMPNO, ENAME 그리고 DEPTNO 열만을 포함하는 EMP 테이블의 구조를 기초로EMPLOYEE2 테이블을 생성하세요. 새 테이블에서 ID, LAST_NAME과 DEPT_ID로 열 이름을 지정하세요.

6. 5.에서 생성한 EMPLOYEE2 테이블에서 LAST_NAME 필드를 10-->30으로 변경하세요.
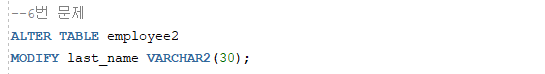
'데이터분석 공부 > DBMS 공부' 카테고리의 다른 글
| DBMS(오라클) : 롤, 동의어, 계층적 질의문, Export, Import (0) | 2022.07.06 |
|---|---|
| DBMS(오라클) : 주석, 데이터무결성, 인덱스, 뷰, DCL, DDL, DML (0) | 2022.07.05 |
| DBMS(오라클) : HAVING 절, JOIN 함수 (0) | 2022.07.01 |
| DBMS(오라클) : 숫자함수, 날짜함수, 일반함수, 그룹함수 (0) | 2022.06.30 |
| DBMS(오라클) : ORDER BY문, SQL-PLUS (0) | 2022.06.29 |



