
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 대용량 데이터 이행
- 측정계
- K-MOOC
- 코테
- 마이데이터 개념과 원칙
- K-MOOC 매치업 강좌
- 대용량데이터 처리방안
- 마이데이터 개념
- 계층적질의문
- GROUP함수
- sql
- 백준
- 오라클
- 코딩테스트
- 대용량 데이터 Batch
- 대용량 데이터 처리
- 무결성제약조건
- 데이터 허브
- ETCL
- K-MOOC 3주차
- 고전압안전
- 데이터 이행
- 1주차:메타데이터와 데이터표준화
- 2022 마이데이터 국민참여단 후기
- EBH
- 마이데이터 비즈니스 모델
- 2주차 : ETL/CDC
- 마이데이터 국민참여단
- 구름Level
- dbms
- Today
- Total
어제보다 더 나은 나
DBMS(오라클) : 주석, 데이터무결성, 인덱스, 뷰, DCL, DDL, DML 본문
* 주석 : 테이블이나 칼럼에 최대 2000 바이트까지 주석을 추가

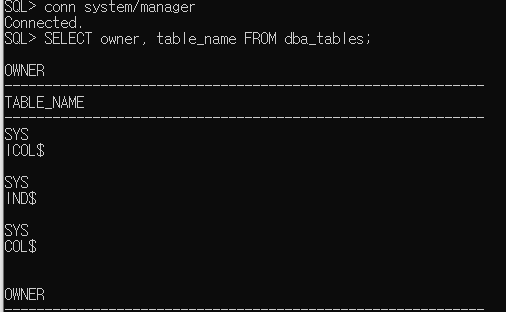
* 데이터 사전
=> 사용자와 데이터베이스 자원을 효율적으로 관리하기 위한 다양한 정보를 저장하는 시스템 테이블의 집합
=> 사전 내용의 수정은 오라클 서버만 가능
=> 데이버베이스 관리자나 일반 사용자는 읽기 전용 뷰에 의해 데이터 사전의 내용 조회만 가능
=> 용도에 따라 USER, ALL, DBA 접두어를 사용하여 분류
=> USER_ : 객체의 소유자만 접근 가능한 데이터 사전 뷰
=> ALL_ : 자기 소유 또는 권한을 부여 받은 객체만 접근 가능한 데이터 사전 뷰
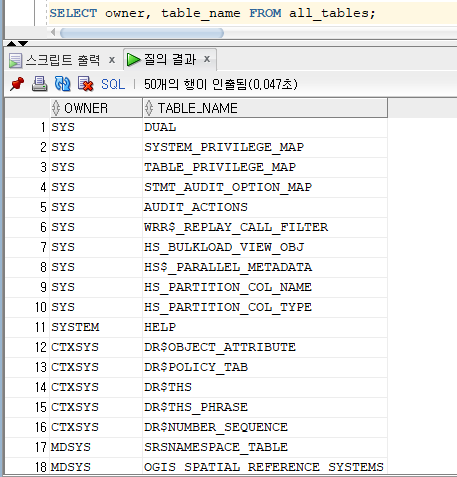
=> DBA_ : 데이터베이스 관리자만 접근 가능한 데이터 사전 뷰
* 데이터 무결성
=> 데이터의 정확성과 일관성을 보장
=> 테이블 생성 시 무결성 제약조건을 정의 가능
=> 테이블에 대해 정의, 데이터 딕셔너리에 저장되므로 응용 프로그램에서 입력된 모든 데이터에 대해 동일하게 적용
=> 제약 조건을 활성화, 비활성화 할 수 있는 융통성
=> 종류 : NOT NULL, 고유키, 기본키, 참조키, CHECK
* NOT NULL : 해당 칼럼의 값이 NULL을 가질 수 없다는 것을 정의하는 제약조건
* 고유키 (Unique Key) 무결성 제약 조건 : 한 테이블 내에서 칼럼이 동일한 값을 가질 수 없음을 정의하는 제약조건
* 기본키 (Primary Key) 무결성 제약 조건 : 하나 이상의 칼럼에 의해 테이블의 모든 행을 구별하기 위한 식별자를 정의하기 위한 제약조건
* 참조 무결성 제약 조건 : 한 테이블의 칼럼 값이 아닌, 다른 테이블의 칼럼 값 중에 하나와 일치시키기 위한 제약조건
* CHECK 무결정 제약 조건 : 칼럼에서 허용 가능한 데이터의 범위나 조건을 지정, 하나의 칼럼에 여러 개의 CHECK 무결성 제약조건 지정 가능
* 무결성 제약 조건 생성 방법
=> 테이블 생성과 동시에 정의
=> 테이블 생성 후 추가, 삭제 가능
=> 제약조건명을 지정하지 않으면 SYS_Cn 형태로 자동생성

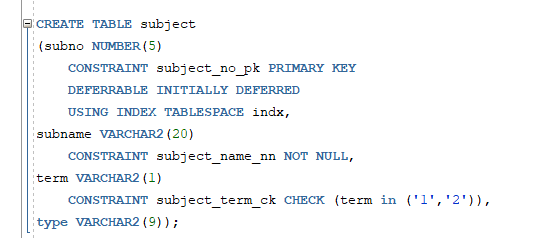

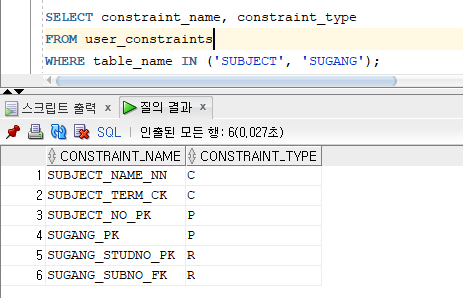
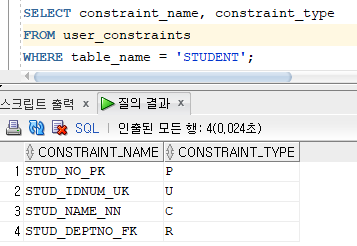
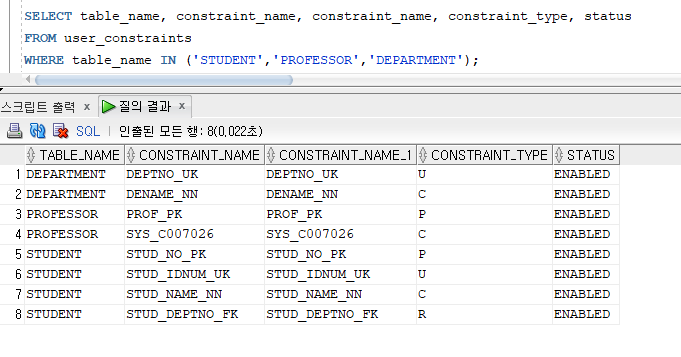
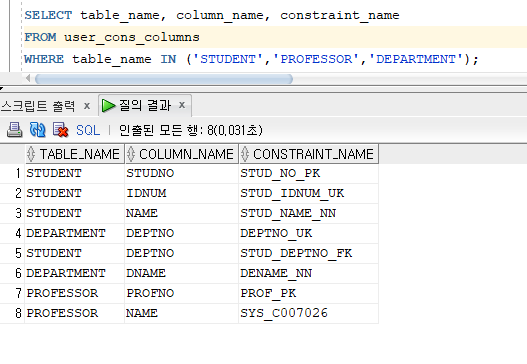
* 무결성 제약조건 조회
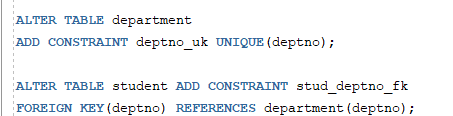
* 기존 테이블에 무결성 제약조건 추가
=> NULL을 제외한 무결성 제약조건 추가 : ALTER...ADD CONSTRINTS 명령문 사용


=> NULL 무결성 제약조건 추가 : ALTER TABLE...MODIFY 명령문 사용

# 예제 : 부서 테이블의 dname에 NOT NULL 무결성 제약조건을 추가해라.

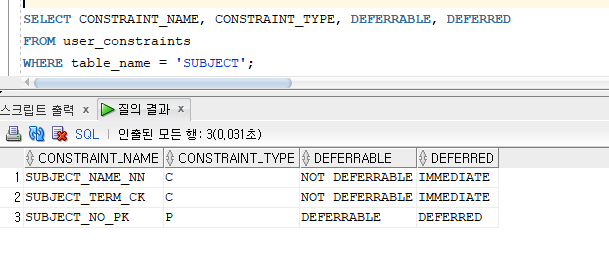
* 무결성 제약조건에 의한 DML 명령문의 영향
=> 즉시 제약조건(immediate constraints)에 위배되는 데이터 입력 시 : 테이블에 데이터를 먼저 입력한 다음 무결성 제약조건을 위반하는 명령문을 롤백
=> 지연 제약조건(deferred constraints)에 위배되는 데이터 입력 시 : 트랙잭션 내의 DML 명령문에서 제약조건 검사를 COMMIT 시점에서 한꺼번에 처리하여 트랜잭션의 처리 성능을 향상시키기 위해 사용
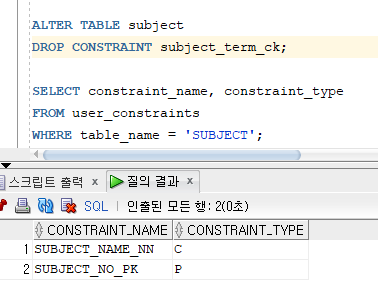
* 무결성 제약조건 삭제
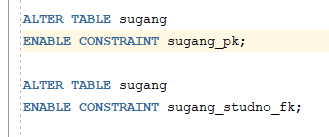
* 대용량 데이터 초기 입력시 무결성 제약조건을 일시적으로 비활성화하여 데이터를 입력한 다음, 비활성화된 무결성 제약조건은 다시 활성화
=> ALTER TABLE 명령문에서 ENABLE 또는 DISABLE절 사용

* 인덱스 : SQL명령문의 처리속도를 향상시키기 위해 칼럼에 대해 생성하는 객체, 포인터를 이용하여 테이블에 저장된 데이터를 랜덤 액세스하기 위한 목적으로 사용
* 인덱스가 효율적인 경우 : WHERE 절이나 조건절에서 자주 사용되는 칼럼, 테이블에 저장된 데이터의 변경이 드문 경우
* 고유 인덱스(Unique Index) : 유일한 값을 가지는 칼럼에 대해 생성하는 인덱스로 모든 인덱스 키는 하나의 테이블의 행과 연결

=> 만일 부서이름이 중복되면 고유 인덱스가 생성되지 않는다.
* 비고유 인덱스(Index) : 중복된 값을 가지는 칼럼에 대해 생성하는 인덱스로 하나의 인덱스 키는 테이블의 여러 행과 연결될 수 있다.

* 단일 인덱스 : 하나의 칼럼으로만 구성된 인덱스
* 결합 인덱스 : 2개 이상의 칼럼을 결합하여 생성하는 인덱스

* DECENDING INDEX : 칼럼별로 정렬순서를 별도로 지정하여 결합 인덱스를 생성하기 위한 방법

* 함수 기반 인덱스 : 칼럼에 대한 연산이나 함수의 계산 결과를 인덱스로 생성 가능, INSERT와 UPDATE시에는 새로운 값을 인덱스에 추가
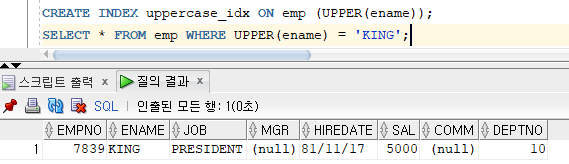

* 인덱스 실행 경로 확인
=> SQL 명령문이 내부적으로 처리되는 경로
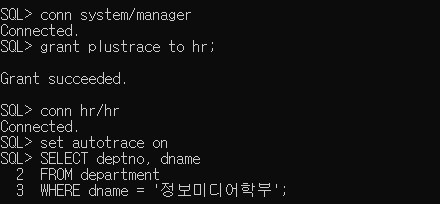
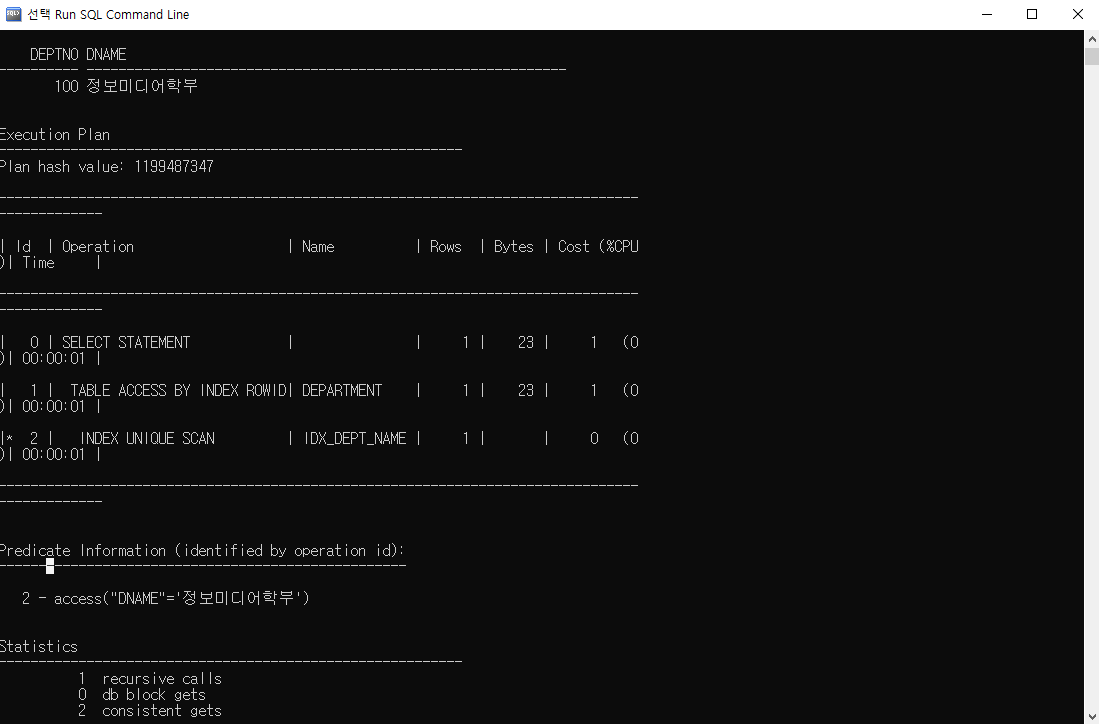
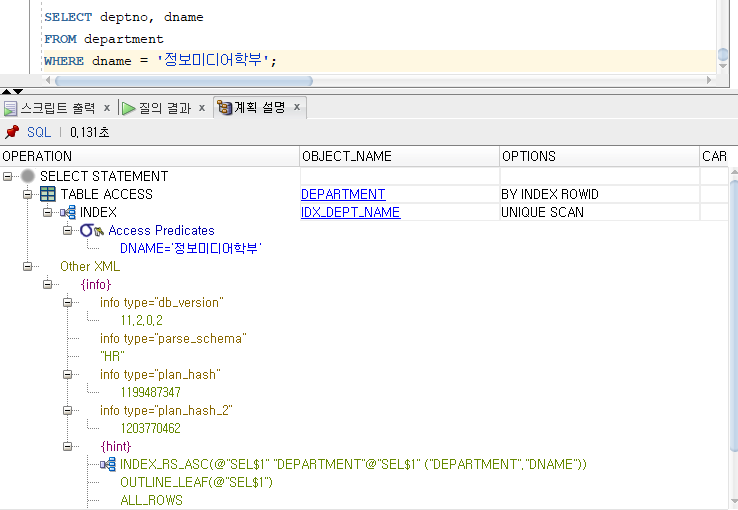
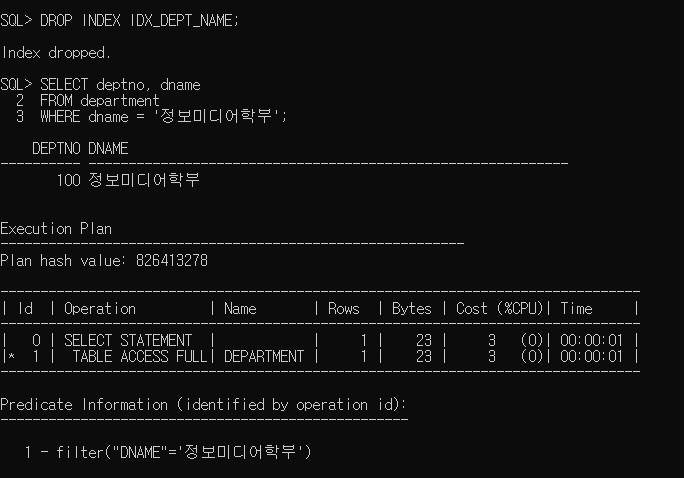
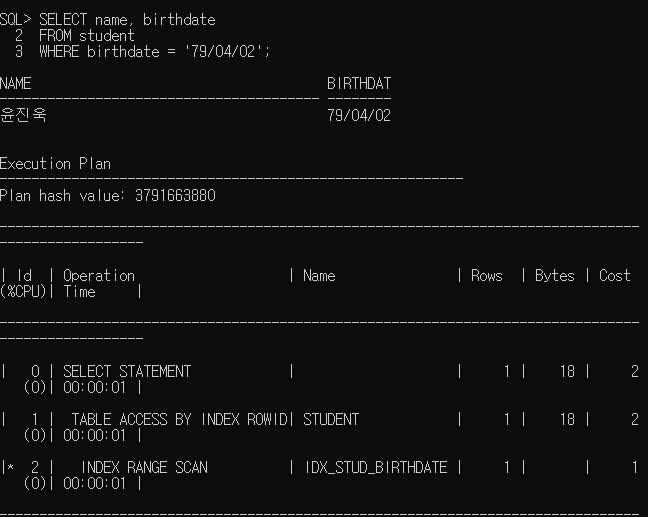
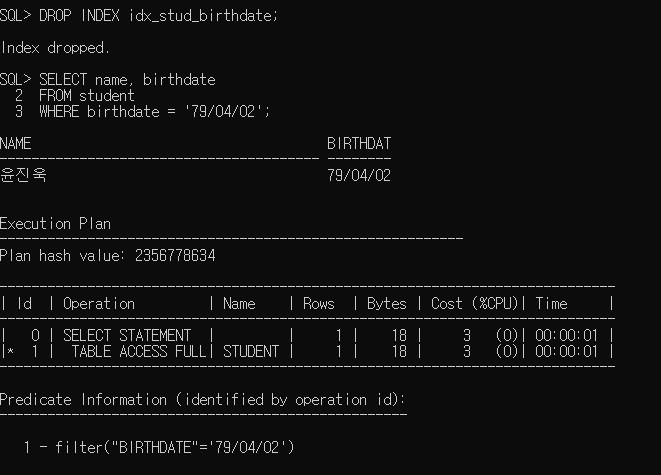
* 인덱스 관리
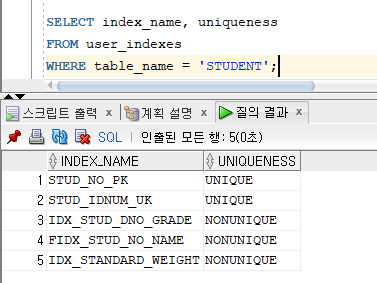
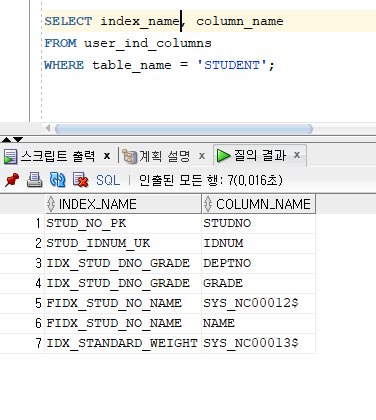
* 인덱스 정보 조회
=> USER_INDEXES : 인덱스 이름과 유일성 여부 등을 확인


* 뷰 : 하나 이상의 기본 테이블이나 다른 뷰를 이용하여 생성되는 가상 테이블
=> 디스크 저장 공간 할당인 안됨.
=> 전체 데이터 중에서 일부만 접근할 수 있도록 제한
=> 뷰에 대한 수정 결과는 뷰를 정의한 기본 테이블에 적용
=> 뷰의 장점 : 보안, 사용자 편의점
* 단순 뷰 : 하나의 기본 테이블에 의해 정의한 뷰, 단순 뷰에 DML 명령문의 실행 결과 기본 테이블에 반영
* 복합 뷰 : 2개 이상의 기본 테이블로 구성한 뷰. DISTINCT, 그룹함수, GROUP BY, START WITH CONNECT BY, ROWNUM을 포함 할 수 없음.
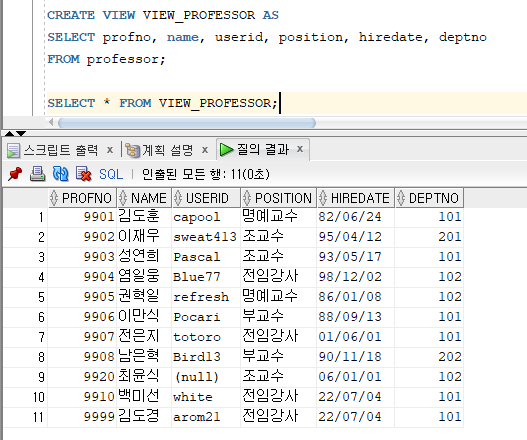
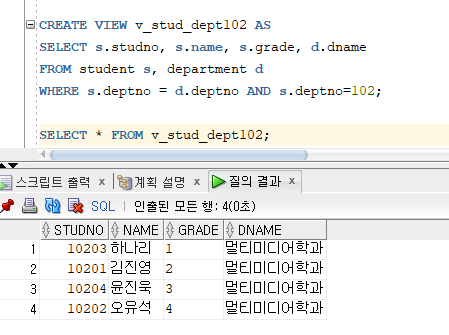
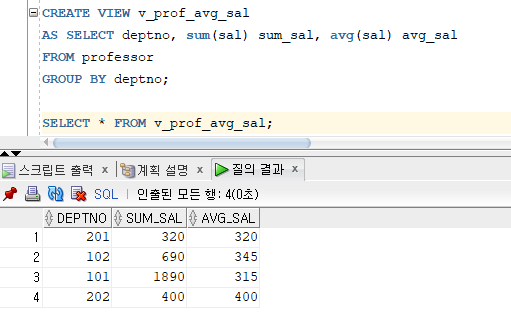
* 뷰 생성
=> CREATE VIEW 명령문 사용
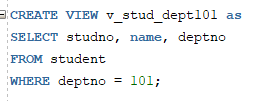
* 인라인 뷰(INLINE VIEW) :
=> FROM 절에서 참조하는 테이블의 크기가 클 경우, 필요한 행과 칼럼만으로 구성된 집합을 재정의하여 질의문을 효율적으로 구성
=> FROM 절에서 서브쿼리를 사용하여 생성한 임시 뷰
=> SQL 명령문이 실행되는 동안만 임시적으로 정의
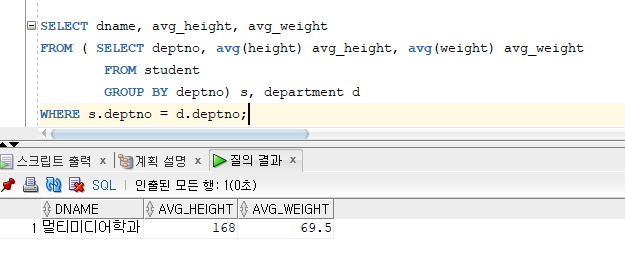
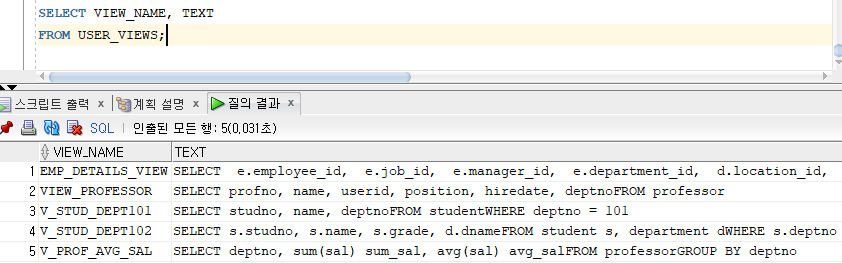
* USER_VIEWS : 사용자가 생성한 모든 뷰에 대한 정의를 저장
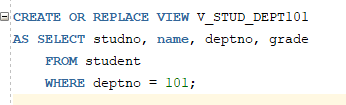
* 뷰의 변경 : 기존 뷰에 대한 정의를 삭제한 후 재생성, CREATE 명령문에서 OR REPLACE 옵션을 이용하여 재생성
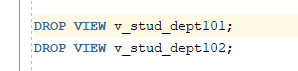
* 뷰의 삭제
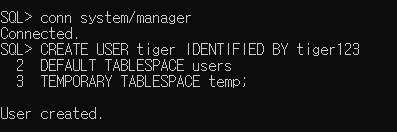
* 시스템 권한 부여
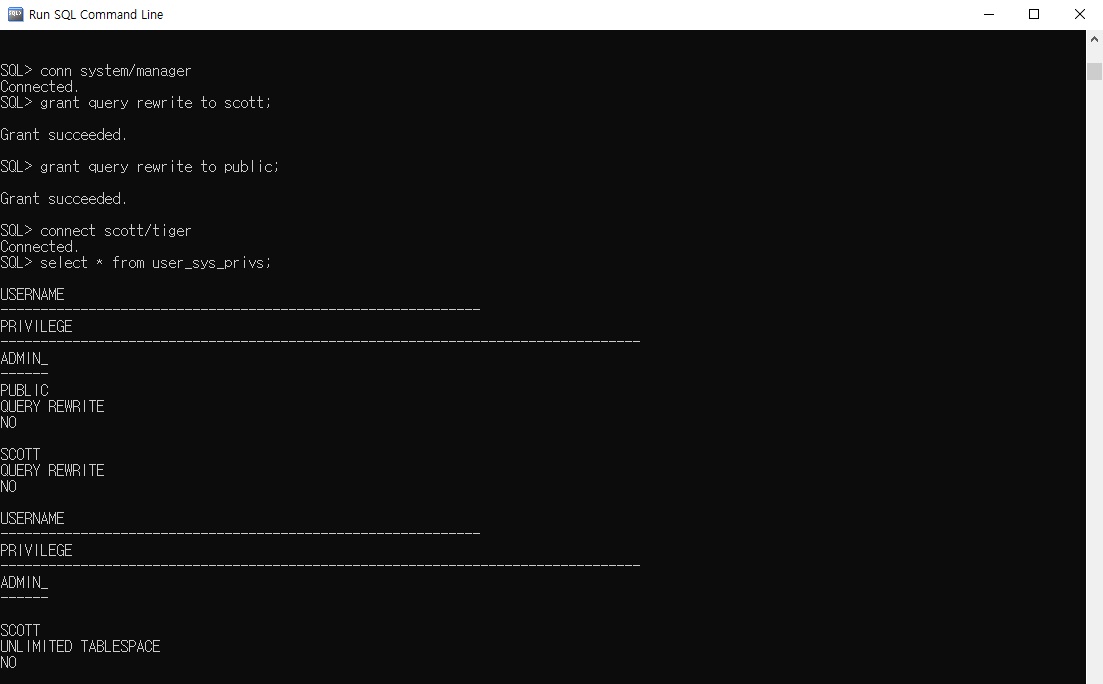
(1)


(2)
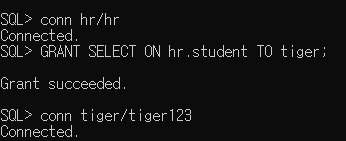
(3)

* 권한 철회
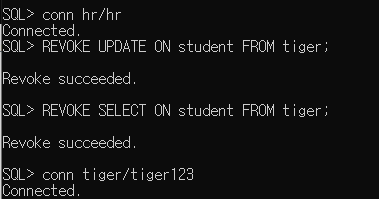
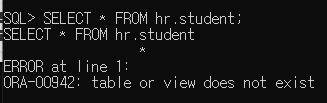
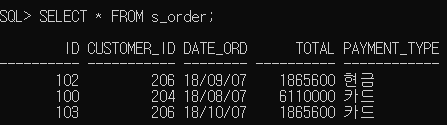
# 예제





5. s_order 테이블의 103번 주문의 지불방식을 ‘카드’로 변경해 보세요.


학과별 최대키를 구하고 최대키를 가진 학생의 학과명, 최대키, 이름, 키를 출력하세요.(결과는 아래~)
학과명 최대키 이름 키
-------------------------------------
멀티미디어학과 177 오유석 177
컴퓨터공학과 186 서재진 186
전자공학과 184 조명훈 184

'데이터분석 공부 > DBMS 공부' 카테고리의 다른 글
| DBMS(오라클) : 롤, 동의어, 계층적 질의문, Export, Import (0) | 2022.07.06 |
|---|---|
| DBMS(오라클) : 서브쿼리, DDL, DML, DCL, TCL, 시퀀스 (0) | 2022.07.04 |
| DBMS(오라클) : HAVING 절, JOIN 함수 (0) | 2022.07.01 |
| DBMS(오라클) : 숫자함수, 날짜함수, 일반함수, 그룹함수 (0) | 2022.06.30 |
| DBMS(오라클) : ORDER BY문, SQL-PLUS (0) | 2022.06.29 |



